
Just the other day I cam across UC Android’s MSRP parser implementation. I was astonished, left speechless. Gazing paralyzed at the code I resisted the urge to run screaming to the development manager and demand that the author of this gem will be publically hanged on the next weekly happy hour. Instead, being the good soul that i am, I decided to take this code as a test case to demonstrate how can we increase Android code efficiency.
I will try to demonstrate:
- Can we increase this code efficiency? Maintainability? Performance?
- Is it worth making the effort?
Here is the original code (with minor modifications: using generic exceptions and replacing the proprietary logger with the Android standard Log calls):
package com.example.test;
import android.util.Log;
import java.io.UnsupportedEncodingException;
import java.net.URI;
import java.util.HashMap;
import java.util.Observable;
import java.util.StringTokenizer;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class MsrpParser extends Observable {
private static final String TAG = "MsrpParser";
private static final int TRANSACTION_ID_MAX_LEN = 31;
private static final int TRANSACTION_ID_MIN_LEN = 2;
private static int HTAB = 0x09;
final static int SP = 0x20;
final static int CR = 0x0D;
final static int LF = 0x0A;
private static final int UNKNOWN = -2;
final static String CRLF = "\r\n";
final static String TO_PATH = "To-Path";
final static String FROM_PATH = "From-Path";
final static String MESSAGE_ID = "Message-ID";
final static String SUCCESS_REPORT = "Success-Report";
final static String FAILURE_REPORT = "Failure-Report";
final static String BYTE_RANGE = "Byte-Range";
final static String STATUS = "Status";
final static String CONTENT_TYPE = "Content-Type";
private int cursor = 0;
private stackState state = stackState.Waiting;
private StringBuilder buffer = null;
private byte[] appendedBytesArray;
MsrpObject o = new MsrpObject();
public MsrpParser() {
deleteObservers();
}
enum stackState {
Waiting, Processing;
}
enum MsrpMessageType {
SEND, REPORT, RESPONSE, OTHER;
}
public class MsrpObject {
MsrpMessageType type = MsrpMessageType.OTHER;
int code = -1;
String comment = "";
String transactionId = "";
HashMap<String, String> headers = null;
String body = "";
String content = "";
boolean complete = false;
char continuationFlag;
/** Headers */
URI fromPath;
URI toPath;
String messageID;
boolean successReport;
String failureReport = "no";
int[] byteRange = new int[2];
String contentType = "";
int totalBytes;
StatusHeader status = null;
void clear() {
type = MsrpMessageType.OTHER;
code = -1;
comment = "";
transactionId = "";
complete = false;
if (headers != null)
headers.clear();
headers = null;
body = "";
content = "";
continuationFlag = '\u0000';
fromPath = null;
toPath = null;
messageID = "";
successReport = false;
failureReport = "no";
byteRange = new int[2];
totalBytes = 0;
contentType = "";
status = null;
}
@Override
protected MsrpObject clone() {
MsrpObject o = new MsrpObject();
o.type = this.type;
o.code = this.code;
o.comment = this.comment;
o.transactionId = this.transactionId;
o.headers = new HashMap<String, String>();
for (String key : this.headers.keySet()) {
o.headers.put(key, this.headers.get(key));
}
o.body = this.body;
o.content = this.content;
o.complete = this.complete;
o.continuationFlag = this.continuationFlag;
o.fromPath = this.fromPath;
o.toPath = this.toPath;
o.messageID = this.messageID;
o.successReport = this.successReport;
o.failureReport = this.failureReport;
o.byteRange[0] = this.byteRange[0];
o.byteRange[1] = this.byteRange[1];
o.totalBytes = this.totalBytes;
o.contentType = this.contentType;
if (status != null) {
o.status = this.status.clone();
}
return o;
}
}
/**
* simple state machine for parsing MSRP messages.
*
* @param data
* @param totalRead
*/
public void parse(byte[] data, int totalRead) {
// add new data to buffer or append
try {
if (data != null) {
// if no older data appended - create the byte array holding the message bytes
if (appendedBytesArray == null) {
appendedBytesArray = new byte[totalRead];
System.arraycopy(data, 0, appendedBytesArray, 0, totalRead);
} else {
// if older data appended - append new bytes using a temp array
byte[] olderData = appendedBytesArray;
appendedBytesArray = new byte[olderData.length + totalRead];
System.arraycopy(olderData, 0, appendedBytesArray, 0, olderData.length);
System.arraycopy(data, 0, appendedBytesArray, olderData.length, totalRead);
}
// construct the string to append from the appended bytes array
buffer = new StringBuilder(new String(appendedBytesArray, "UTF8"));
Log.d(TAG, "num of bytes = " + appendedBytesArray.length + ", parse string: " + buffer);
}
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
boolean waitForMore = false;
// run on buffer as long as it contains data
while (buffer != null && buffer.length() > 0 && !waitForMore) {
Log.d(TAG, "state: " + state);
try {
switch (state) {
// waiting state is the starting state. it is reached after a buffer has been processed completely
case Waiting:
if (o.complete) {
Log.d(TAG, "completed message: " + o.transactionId);
setChanged();
notifyObservers(o.clone());
o.clear();
}
if (analayzeMsrpMessage(o)) {
if (o.type == MsrpMessageType.SEND || o.type == MsrpMessageType.REPORT
|| o.type == MsrpMessageType.RESPONSE) {
state = stackState.Processing;
}
} else {
Log.d(TAG, "waiting for more data: " + o.transactionId);
waitForMore = true;
}
break;
case Processing:
if (processMsrpMessage(o)) {
Log.d(TAG, "Processing completed -> Waiting: " + o.transactionId);
setChanged();
notifyObservers(o.clone());
o.clear();
state = stackState.Waiting;
} else {
Log.d(TAG, "waiting for more data: " + o.transactionId);
waitForMore = true;
}
break;
default:
break;
}
} catch (Exception e) {
Log.w(TAG, "Caught ProtocolViolationException - something went wrong, continue cautiously");
}
}
}
/**
* To-Path = "To-Path:" SP MSRP-URI *( SP MSRP-URI )
* From-Path = "From-Path:" SP MSRP-URI *( SP MSRP-URI )
* Message-ID = "Message-ID:" SP ident
* Success-Report = "Success-Report:" SP ("yes" / "no" )
* Failure-Report = "Failure-Report:" SP ("yes" / "no" / "partial" )
* Byte-Range = "Byte-Range:" SP range-start "-" range-end "/" total
* Status = "Status:" SP namespace SP status-code [SP comment]
* Content-Type = "Content-Type:" SP media-type
*
* @param o
* @throws ProtocolViolationException
*/
private static void processMsrpHeaders(MsrpObject o) throws Exception {
Log.v(TAG, "processMsrpHeaders");
if (o.body == null) {
return;
}
String body = o.body;
StringTokenizer lines = new StringTokenizer(body, CRLF);
if (o.headers == null) {
o.headers = new HashMap<String, String>();
}
while (lines.hasMoreTokens()) {
String token = lines.nextToken();
int index = token.indexOf(":");
if (index == -1) {
Log.d(TAG, "processMsrpHeaders found no key-value pair in this line: " + token);
continue;
}
String key = token.substring(0, index);
String value = token.substring(index + 1).trim();
if (key.equalsIgnoreCase(TO_PATH)) {
handleToPath(o, value);
} else if (key.equalsIgnoreCase(FROM_PATH)) {
handleFromPath(o, value);
} else if (key.equalsIgnoreCase(MESSAGE_ID)) {
handleMessageId(o, value);
} else if (key.equalsIgnoreCase(SUCCESS_REPORT)) {
handleSuccessReport(o, value);
} else if (key.equalsIgnoreCase(FAILURE_REPORT)) {
handleFailureReport(o, value);
} else if (key.equalsIgnoreCase(BYTE_RANGE)) {
handleByteRange(o, value);
} else if (key.equalsIgnoreCase(STATUS)) {
handleStatus(o, value);
} else if (key.equalsIgnoreCase("Content-Type")) {
handleContentType(o, value);
// this is the last header in the MSRP message
break;
} else {
o.headers.put(key, value);
Log.v(TAG, "Found ext-header: " + key + ": " + value);
}
}
}
private static void handleToPath(MsrpObject mo, String headerValue) throws Exception {
Log.v(TAG, TO_PATH + " " + headerValue);
try {
mo.toPath = URI.create(headerValue);
} catch (IllegalArgumentException e) {
Log.w(TAG, "URI To-Path construction failed");
throw new Exception();
}
}
private static void handleFromPath(MsrpObject mo, String headerValue) throws Exception {
Log.v(TAG, FROM_PATH + " " + headerValue);
try {
mo.fromPath = URI.create(headerValue);
} catch (IllegalArgumentException e) {
Log.w(TAG, "URI To-Path construction failed");
throw new Exception();
}
}
private static void handleMessageId(MsrpObject mo, String headerValue) throws Exception {
Log.v(TAG, MESSAGE_ID + " " + headerValue);
for (int i = 0; i < headerValue.length(); i++) {
if (!MsrpParser.isCharIdent(headerValue.charAt(i))) {
Log.w(TAG, "Message-ID contains illegal character: " + headerValue.charAt(i));
throw new Exception();
}
}
mo.messageID = headerValue;
}
private static void handleSuccessReport(MsrpObject mo, String headerValue) throws Exception {
Log.v(TAG, SUCCESS_REPORT + " " + headerValue);
if (headerValue.equals("yes")) {
mo.successReport = true;
} else if (headerValue.equals("no")) {
mo.successReport = false;
} else {
Log.w(TAG, "Error, unknown Success-Report value: " + headerValue);
throw new Exception();
}
}
private static void handleFailureReport(MsrpObject mo, String headerValue) throws Exception {
Log.v(TAG, FAILURE_REPORT + " " + headerValue);
if (headerValue.equals("yes") || headerValue.equals("no") || headerValue.equals("partial")) {
mo.failureReport = headerValue;
} else {
Log.w(TAG, "Error, unknown Failure-Report value: " + headerValue);
throw new Exception();
}
}
private static void handleByteRange(MsrpObject mo, String headerValue) throws Exception {
Log.v(TAG, BYTE_RANGE + " " + headerValue);
Pattern byteRangePattern = Pattern.compile("(\\p{Digit}+)-(\\p{Digit}+|\\*)/(\\p{Digit}+|\\*)",
Pattern.DOTALL | Pattern.CASE_INSENSITIVE);
Matcher byteRangeMatcher = byteRangePattern.matcher(headerValue);
if (byteRangeMatcher.matches()) {
try {
mo.byteRange[0] = Integer.parseInt(byteRangeMatcher.group(1));
if (byteRangeMatcher.group(2).contentEquals("*")) {
mo.byteRange[1] = UNKNOWN;
} else {
mo.byteRange[1] = Integer.parseInt(byteRangeMatcher.group(2));
}
if (byteRangeMatcher.group(3).contentEquals("*")) {
mo.totalBytes = UNKNOWN;
} else {
mo.totalBytes = Integer.parseInt(byteRangeMatcher.group(3));
}
} catch (NumberFormatException e) {
Log.w(TAG, "Error, erroneously parsed part of the Byte-Range field as an INT");
throw new Exception();
}
}
}
private static void handleStatus(MsrpObject mo, String headerValue) throws Exception {
Log.v(TAG, STATUS + " " + headerValue);
Pattern statusHeaderPattern = Pattern.compile("(\\p{Digit}{3})\\s(\\p{Digit}{3})\\s([\\p{Alnum},\\s]+)",
Pattern.DOTALL | Pattern.CASE_INSENSITIVE);
Matcher statusHeaderMatcher = statusHeaderPattern.matcher(headerValue);
if (statusHeaderMatcher.matches()) {
String namespace = statusHeaderMatcher.group(1);
String statusCode = statusHeaderMatcher.group(2);
String comment = statusHeaderMatcher.group(3);
try {
mo.status = new StatusHeader(namespace, statusCode, comment);
} catch (Exception e) {
Log.w(TAG, "Processing Status failed " + headerValue);
throw new Exception();
}
}
}
private static void handleContentType(MsrpObject o, String headerValue) throws Exception {
Log.i(TAG, CONTENT_TYPE + " " + headerValue);
o.contentType = headerValue;
int startIndex = o.body.indexOf(CONTENT_TYPE);
startIndex = o.body.indexOf(CRLF + CRLF, startIndex);
startIndex += (CRLF + CRLF).length();
try {
String content = o.body.substring(startIndex);
o.content = content;
Log.v(TAG, "Content: " + content);
} catch (IndexOutOfBoundsException e) {
Log.w(TAG, "Content processing failed " + headerValue);
throw new Exception();
}
}
/**
* this function will process the message body:
* - extract the headers
* - extract the body
* - identify the end-line
*
* @param o
* @return
* @throws ProtocolViolationException
*/
private boolean processMsrpMessage(MsrpObject o) throws Exception {
Log.v(TAG, "processMsrpMessage");
boolean result = false;
try {
int tempCursor = cursor;
boolean messageEnded = false;
// end-line = "-------" transact-id continuation-flag CRLF
while (!messageEnded) {
if (buffer.charAt(tempCursor) == '-'
&& buffer.charAt(tempCursor + 1) == '-'
&& buffer.charAt(tempCursor + 2) == '-'
&& buffer.charAt(tempCursor + 3) == '-'
&& buffer.charAt(tempCursor + 4) == '-'
&& buffer.charAt(tempCursor + 5) == '-'
&& buffer.charAt(tempCursor + 6) == '-') {
int i = 0;
// transact-id
for (; i < o.transactionId.length(); i++) { if (o.transactionId.charAt(i) == buffer.charAt(tempCursor + 7 + i)) { result = true; continue; } else { result = false; break; } } // continuation-flag "+" / "$" / "#" if (result && (buffer.charAt(tempCursor + 7 + i) == '+' || buffer.charAt(tempCursor + 7 + i) == '$' || buffer.charAt(tempCursor + 7 + i) == '#')) { o.continuationFlag = buffer.charAt(tempCursor + 7 + i); result = true; } else { result = false; } // CRLF if (result) { if (buffer.charAt(tempCursor + 8 + i) == CR && buffer.charAt(tempCursor + 9 + i) == LF) { cursor = tempCursor + 10 + i; result = true; } else { result = false; } } if (result) { messageEnded = true; break; } } tempCursor++; } if (messageEnded) { Log.d(TAG, "processing found message end, taking from string buffer (0," + tempCursor + ")"); o.body = buffer.substring(0, tempCursor); o.complete = true; int numOfBytesToDelete = buffer.substring(0, cursor).getBytes("UTF8").length; buffer.delete(0, cursor); Log.d(TAG, "processing - deleted " + cursor + " chars from buffer, need to delete " + numOfBytesToDelete + " bytes from appended byte array"); cursor = 0; // check if there was some more data remained inthe buffer belonging to another message if (buffer.length() > 0) {
Log.d(TAG,
"processing buffer has data of another message going to delete the processed message bytes from the appended byte array");
// remove the new message body bytes from the appended byte array to remain with data belonging to
// another message that may be cut due to UTF8 input
byte[] temp1 = new byte[appendedBytesArray.length - numOfBytesToDelete];
System.arraycopy(appendedBytesArray, numOfBytesToDelete, temp1, 0, appendedBytesArray.length
- numOfBytesToDelete);
appendedBytesArray = temp1;
Log.d(TAG, "deleted " + numOfBytesToDelete + " bytes from appended byte array");
} else {
Log.d(TAG, "processing buffer has no more data going to reset buffer and counters");
appendedBytesArray = null;
}
processMsrpHeaders(o);
// reset this as we need it to new messages to come
}
// if did not get to process the entire message and have to wait till the appended byte array contains the
// entire message
// we have the data backed up as bytes so we can delete the string buffer.
// anyway delete all buffer - we backed the remaining data in the appended byte array
buffer = null;
} catch (StringIndexOutOfBoundsException e) {
Log.d(TAG, "no more chars in buffer restart from zero next time");
result = false;
buffer = null;
} catch (UnsupportedEncodingException e) {
Log.e(TAG, e.getMessage(), e);
result = false;
buffer = null;
}
return result;
}
/**
* this function will identify the message as request or response and extract the transaction id and method/code
*
* @param o
* @return
*/
private boolean analayzeMsrpMessage(MsrpObject o) {
Log.d(TAG, "analayzeMsrpMessage");
boolean result = false;
try {
// start of message "MSRP SP"
if (buffer.charAt(cursor++) == 'M' && buffer.charAt(cursor++) == 'S' && buffer.charAt(cursor++) == 'R'
&& buffer.charAt(cursor++) == 'P' && buffer.charAt(cursor++) == SP) {
result = true;
}
// start of transaction id
if (result) {
StringBuilder transactionId = new StringBuilder();
for (;; cursor++) {
char c = buffer.charAt(cursor);
if (isCharIdent(c)) {
transactionId.append(c);
// transaction is is limited at 31
if (o.transactionId.length() > TRANSACTION_ID_MAX_LEN) {
Log.i(TAG, "transaction Id is longer than 31");
result = false;
break;
}
// when reaching space - stop
} else if (c == SP) {
if (transactionId.length() > TRANSACTION_ID_MIN_LEN) {
o.transactionId = transactionId.toString();
result = true;
} else {
Log.i(TAG, "transaction Id is shorter than 3");
result = false;
}
break;
} else {
Log.i(TAG, "transaction Id contains illegal char " + c);
result = false;
break;
}
}
} else {
Log.v(TAG, "could not find MSRP prefix");
}
// method or response code
if (result) {
cursor++;
int tempCursor = cursor;
// support only SEND or REPORT
if (buffer.charAt(tempCursor) == 'S'
&& buffer.charAt(tempCursor + 1) == 'E'
&& buffer.charAt(tempCursor + 2) == 'N'
&& buffer.charAt(tempCursor + 3) == 'D') {
cursor = tempCursor + 4;
o.type = MsrpMessageType.SEND;
} else if (buffer.charAt(tempCursor) == 'R'
&& buffer.charAt(tempCursor + 1) == 'E'
&& buffer.charAt(tempCursor + 2) == 'P'
&& buffer.charAt(tempCursor + 3) == 'O'
&& buffer.charAt(tempCursor + 4) == 'R'
&& buffer.charAt(tempCursor + 5) == 'T') {
cursor = tempCursor + 6;
o.type = MsrpMessageType.REPORT;
// response code - 3 digits
} else if (Character.isDigit(buffer.charAt(tempCursor))
&& Character.isDigit(buffer.charAt(tempCursor + 1))
&& Character.isDigit(buffer.charAt(tempCursor + 2))) {
cursor = tempCursor + 2;
String codeNumber = buffer.substring(tempCursor, tempCursor + 3);
if (codeNumber.length() != 3) {
Log.i(TAG, "transaction code is not 3 digits long " + codeNumber);
result = false;
} else {
result = true;
o.type = MsrpMessageType.RESPONSE;
o.code = Integer.valueOf(codeNumber);
// response code comment
if (o.code != -1) {
cursor++;
if (buffer.charAt(cursor) == SP) {
cursor++;
StringBuilder comment = new StringBuilder();
for (;; cursor++) {
char c = buffer.charAt(cursor);
if (isCharUtf8text(c)) {
comment.append(c);
} else {
break;
}
}
if (comment.length() > 0) {
o.comment = comment.toString();
Log.v(TAG, "found comment: " + comment + " for status " + o.code);
}
}
}
}
} else {
Log.i(TAG, "transaction contains illegal code/type " + buffer.charAt(cursor));
result = false;
}
} else {
Log.v(TAG, "could not find transaction id");
}
// at the end of the line there must be CRLF
if (result) {
if (o.type == MsrpMessageType.REPORT || o.type == MsrpMessageType.SEND || o.code != -1) {
if (buffer.charAt(cursor++) == CR && buffer.charAt(cursor) == LF) {
cursor++;
result = true;
} else {
result = false;
}
} else {
Log.v(TAG, "not a send/report transaction response");
}
}
// dump processed buffer - in failure or success
Log.d(TAG, "analayzeMsrpMessage. clearing buffer: " + buffer.subSequence(0, cursor));
int numOfBytesToDelete = buffer.substring(0, cursor).getBytes("UTF8").length;
buffer.delete(0, cursor);
// remove the new message body bytes from the appended byte array to remain with data belonging to
// another message that may be cut due to UTF8 input
byte[] temp1 = new byte[appendedBytesArray.length - numOfBytesToDelete];
System.arraycopy(appendedBytesArray, numOfBytesToDelete, temp1, 0, appendedBytesArray.length
- numOfBytesToDelete);
appendedBytesArray = temp1;
Log.d(TAG, "analyzing - deleted " + cursor + " chars from buffer, deleted " + numOfBytesToDelete
+ " bytes from appended byte array");
} catch (StringIndexOutOfBoundsException e) {
// in case we catch this exception it means that the buffer was consumed but we did not complete the
// processing.
// the processing will restart after receiving more data
e.printStackTrace();
Log.i(TAG, "no more chars in buffer restart from zero next time");
result = false;
} catch (UnsupportedEncodingException e) {
Log.e(TAG, e.getMessage(), e);
result = false;
}
// erase MsrpObject in case of parsing failure
if (!result) {
o.clear();
}
cursor = 0;
return result;
}
// ident 0-9 / A-Z / a-z / "." / "-" / "+" / "%" / "="
public static boolean isCharIdent(char c) {
if ((c >= 0x30 && c <= 0x39) || (c >= 0x41 && c <= 0x5a) || c == 0x2e || c == 0x2d || c == 0x25 || c == 0x3d || c == 0x2b || (c >= 0x61 && c <= 0x7a)) { return true; } return false; } // utf8text = *(HTAB / %x20-7E / UTF8-NONASCII) // UTF8-NONASCII = %xC0-DF 1UTF8-CONT // / %xE0-EF 2UTF8-CONT // / %xF0-F7 3UTF8-CONT // / %xF8-Fb 4UTF8-CONT // / %xFC-FD 5UTF8-CONT // UTF8-CONT = %x80-BF public static boolean isCharUtf8text(char c) { if (c == HTAB || (c >= 0x20 && c <= 0x7E) || (c >= 0xC0 && c <= 0xDF) || (c >= 0xE0 && c <= 0xEF) || (c >= 0xF0 && c <= 0xF7) || (c >= 0xF8 && c <= 0xFB) || (c >= 0xFC && c <= 0xFD) || (c >= 0x80 && c <= 0xBF)) {
return true;
}
return false;
}
}
So we have 700 lines of code for the parser. Let’s try it out. We’ll try to parse the following MSRP message:
MSRP f214bc8-10011-5a419215 SEND To-Path: msrp://12.130.62.37:2855/497192-29899-497192;tcp From-Path: msrp://10.113.20.46:5080/f15ea40-10011-187f573;tcp Message-ID: ded60d0-10011-511aa7ef Failure-Report: yes Byte-Range: 1-134/134 Content-Type: text/plain X-ATT-GUID:00000022965879515481801152355861 X-ATT-TS: FROM:sip:pu_mvmaryoqq@uccentral.att.com TEXT:Thanks -------f214bc8-10011-5a419215$";
And here is our test code:
public void testMsrp() {
final String msrpMessage = "MSRP f214bc8-10011-5a419215 SEND\r\nTo-Path: msrp://12.130.62.37:2855/497192-29899-497192;tcp\r\nFrom-Path: msrp://10.113.20.46:5080/f15ea40-10011-187f573;tcp\r\nMessage-ID: ded60d0-10011-511aa7ef\r\nFailure-Report: yes\r\nByte-Range: 1-134/134\r\nContent-Type: text/plain\r\n\r\nX-ATT-GUID:00000022965879515481801152355861\r\nX-ATT-TS:\r\nFROM:sip:pu_mvmaryoqq@uccentral.att.com\r\nTEXT:Thanks\r\n-------f214bc8-10011-5a419215$\r\n";
final byte[] msrpBytes = msrpMessage.getBytes();
final int count = 1000;
final long start = System.currentTimeMillis();
for(int i = 0; i < count; i++) { final MsrpParser msrpParser = new MsrpParser(); msrpParser.parse(msrpBytes, msrpBytes.length); } Log.v("testMsrp", ">>>>> Parsing Ended, took: " + (System.currentTimeMillis() - start) + " mSec");
}
Parsing this MSRP message 1000 times, took ~35000 mSec, printing 34000+ log lines, allocating thousands of objects.
That’s 35 mSec to parse a message in average!
Those with a sharp eye may comment, without arguing, that the test method itself is inefficient. It allocate new parser object for each pass. That’s true. Looking at the heap dump reveals that 48K objects were allocated (of these more than 2000 are classes), and the shallow heap is more than 2M!!!
Case 1 – Memory allocations and garbage collection
It would have been nice if we could allocate less objects, and give Mr. Dalvik’s poor garbage collector a chance to work more efficiently.
The problem is that the parser doesn’t support restarting or initializing to the initial state:
MsrpParser Class
So we will add a reset method to the parser and change our test code to use it instead of allocation new parser on each pass. Here is the reset method:
public void reset() {
cursor = 0;
buffer = null;
appendedBytesArray = null;
state = stackState.Waiting;
o.clear();
}
and the new test method:
public void testMsrp() {
final String msrpMessage = "MSRP f214bc8-10011-5a419215 SEND\r\nTo-Path: msrp://12.130.62.37:2855/497192-29899-497192;tcp\r\nFrom-Path: msrp://10.113.20.46:5080/f15ea40-10011-187f573;tcp\r\nMessage-ID: ded60d0-10011-511aa7ef\r\nFailure-Report: yes\r\nByte-Range: 1-134/134\r\nContent-Type: text/plain\r\n\r\nX-ATT-GUID:00000022965879515481801152355861\r\nX-ATT-TS:\r\nFROM:sip:pu_mvmaryoqq@uccentral.att.com\r\nTEXT:Thanks\r\n-------f214bc8-10011-5a419215$\r\n";
final byte[] msrpBytes = msrpMessage.getBytes();
final MsrpParser msrpParser = new MsrpParser();
final int count = 1000;
final long start = System.currentTimeMillis();
for(int i = 0; i < count; i++) { msrpParser.parse(msrpBytes, msrpBytes.length); msrpParser.reset(); } Log.v("testMsrp", ">>>>> Parsing Ended, took: " + (System.currentTimeMillis() - start) + " mSec");
}
Running this again gives surprising results – the parsing time has not changed significantly! The numbers of object allocations and heap size also remained pretty much the same.
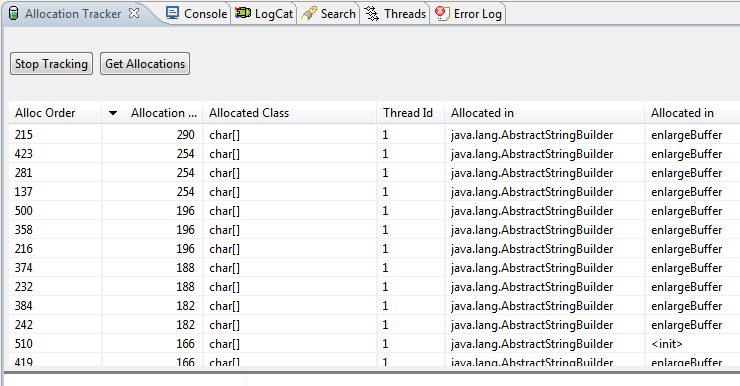
allocations1
What is happening here? Looking at the heap allocation tracker reveals that most allocations occur inside the StringBuilder when the buffer is growing.
Our changes have not mitigated this issue.
Let’s look for example at the code from line 480 to 511. It uses a StringBuilder to extract the transactionId which could be up to 31 characters in length. The StringBuilder is initialized by the default constructor, which will set it’s initial capacity to 16. This means that if there are more than 16 characters in the transactionId (which is 22 in our sample MSRP message) the StringBuilder will need to grow it’s buffer. The growing mechanism is usually multiply by 2, so the new buffer size will be 32 chars. It also means that for every message parse there will be at least 2 allocation for this specific string builder. The solution in this case is simple – set the initial StringBuilder capacity to 31 (because more than that is illegal anyway). We save one re-allocation and even save 1 byte for each message parse. Let’s try the following:
StringBuilder transactionId = new StringBuilder(31);
This shaved a couple of hundreds of mSec from the total parse time (less than half a second). The heap is reduced by less than 1K (but that is expected if we only save 1 byte in each of the 1000 iterations). In this case the effort is not worth while. Maybe the direction should be eliminating the StringBuilder all together? We’ll discuss this in the next case.
Case 2 – The destruction of the famous StringBuilder
I know they’ve told you StringBuilder is more efficient than String, but is it? This article and this one show that there are cases where String could be more efficient than StringBuilder. It depends on the use case and other factors. In our case the use is to append multiple characters to one single continuous string. The size of transactionId is known in advance, and for this particular case, it is usually agreed that char[] will be more efficient than StringBuilder. Other references agree that single character operation with StringBuilder has no advantage over char arrays (though it has some advantage over StringBuffer because it is not synchronized like the StringBuffer operations)..
Let’s try to change the transactionId extraction:
// start of transaction id
if (result) {
char[] transactionId = new char[31];
for (int index = 0;; index++,cursor++) {
char c = buffer.charAt(cursor);
if (isCharIdent(c)) {
// transaction is is limited at 31
if (index >= TRANSACTION_ID_MAX_LEN) {
Log.i(TAG, "transaction Id is longer than 31");
result = false;
break;
}
transactionId[index] = c;
// when reaching space - stop
} else if (c == SP) {
if (index >= TRANSACTION_ID_MIN_LEN) {
o.transactionId = String.valueOf(transactionId, 0, index);
result = true;
} else {
Log.i(TAG, "transaction Id is shorter than 3");
result = false;
}
break;
} else {
Log.i(TAG, "transaction Id contains illegal char " + c);
result = false;
break;
}
}
} else {
Log.v(TAG, "could not find MSRP prefix");
}
Performance and memory allocation figures have not changed significantly. This is probably of the good job the compiler is doing with optimizing the byte code for the StringBuilder code. Without resorting to byte code comparison, it is safe to assume that the efficiency will probably be the same. Unless… What if allocate the char buffer once, and not every parse?
we will define in the MsrpParser class:
final static private char[] transactionId = new char[31];
and remark line 482. Performance is up by about 5% (we gained a whole sec) and memory figures are down by about 3%. Not much, but still something.
Case 3 – Recompile the precompiled
Since the parser uses some reg-ex code, it is only logical that it will pre-compile the patterns to be used (see lines 337 and 363 for example).. However, this was done inside the methods and not on the class level, so the pre-compilation is performed for each parser from scratch. Let’s try to move them to the class and compile them only once:
final static private Pattern byteRangePattern = Pattern.compile("(\\p{Digit}+)-(\\p{Digit}+|\\*)/(\\p{Digit}+|\\*)",
Pattern.DOTALL | Pattern.CASE_INSENSITIVE);
final static private Pattern statusHeaderPattern = Pattern.compile("(\\p{Digit}{3})\\s(\\p{Digit}{3})\\s([\\p{Alnum},\\s]+)",
Pattern.DOTALL | Pattern.CASE_INSENSITIVE);
The average parse time dropps to 25000 mSec! We were able to cut 10 seconds from our initial results. Alas, memory allocations are still about the same 🙁
If we are discussing the parse time or other performance metrics, no such discussion is complete without having a look at the performance analysis of our code:

This will tell us where we focus our optimization efforts.
We see that 97.4% of the time we spent in the parse() method (but obviously we already know that). 12% we do in String.IndexOf and 5% in String.charAt. StringBuilder.charAt uses 20% of our time, and was called 71000 times…
A lot of time is spent in the helper functions isCharIdent (line 629) and isCharUtf8Text (line 645) because they are called to inspect individual characters during the parse. Let’s discuss them a bit.
Case 4 – The reg-ex dilema
The whole purpose of the method analayzeMsrpMessage (line 470), and in particular it’s first section (lines 471 to 579) is to check the MSRP message for the proper format by scanning it char by char.
It may not be such a good approach if we know that a valid MSRP message, that we support could be one of the following 3 cases (which is what this code is checking):
MSRP id SEND CRLF MSRP id REPORT CRLF MSRP id status-code[ comment]CRLF
Maybe a reg-ex approach will be better? usually, reg-ex performance is not comparable to char buffer manipulations, but the code here is very hard to maintain, uses a lot of nested helper function calls (and simply looks ugly to me), not to mention that it hides nested loop in it, and uses the same charAt(index) calls several times…
I decided to replace the analyzeMsrpMessage method (line 409) implementation to one that uses reg-ex:
private boolean analayzeMsrpMessage2(MsrpObject o) {
Log.d(TAG, "analayzeMsrpMessage");
boolean result = false;
try {
Matcher startMatcher = startPattern.matcher(buffer);
if (startMatcher.matches()) {
o.transactionId = startMatcher.group(1);
if(startMatcher.group(2).equals("SEND")) {
o.type = MsrpMessageType.SEND;
} else if(startMatcher.group(2).equals("REPORT")) {
o.type = MsrpMessageType.REPORT;
} else {
o.type = MsrpMessageType.RESPONSE;
o.code = Integer.valueOf(startMatcher.group(2));
if(startMatcher.groupCount() > 2) {
o.comment = startMatcher.group(3);
Log.v(TAG, "found comment: " + o.comment + " for status " + o.code);
}
}
result = true;
} else {
Log.v(TAG, "No match found");
}
// at the end of the line there must be CRLF
if (result) {
while(buffer.charAt(cursor) != CR) cursor++;
if (buffer.charAt(cursor++) == CR && buffer.charAt(cursor) == LF) {
cursor++;
result = true;
} else {
result = false;
}
}
// dump processed buffer - in failure or success
Log.d(TAG, "analayzeMsrpMessage. clearing buffer: " + buffer.subSequence(0, cursor));
int numOfBytesToDelete = buffer.substring(0, cursor).getBytes("UTF8").length;
buffer.delete(0, cursor);
// remove the new message body bytes from the appended byte array to remain with data belonging to
// another message that may be cut due to UTF8 input
byte[] temp1 = new byte[appendedBytesArray.length - numOfBytesToDelete];
System.arraycopy(appendedBytesArray, numOfBytesToDelete, temp1, 0, appendedBytesArray.length - numOfBytesToDelete);
appendedBytesArray = temp1;
Log.d(TAG, "analyzing - deleted " + cursor + " chars from buffer, deleted " + numOfBytesToDelete + " bytes from appended byte array");
} catch (StringIndexOutOfBoundsException e) {
// in case we catch this exception it means that the buffer was consumed but we did not complete the
// processing.
// the processing will restart after receiving more data
e.printStackTrace();
Log.i(TAG, "no more chars in buffer restart from zero next time");
result = false;
} catch (UnsupportedEncodingException e) {
Log.e(TAG, e.getMessage(), e);
result = false;
}
// erase MsrpObject in case of parsing failure
if (!result) {
o.clear();
}
cursor = 0;
return result;
}
Notice how many lines of code where replaced by ~20 lines of reg-ex matcher code.
The precompiled pattern in the class is:
final static private Pattern startPattern = Pattern.compile("^MSRP\\p{Blank}([A-Za-z0-9.+%=-]{2,31})\\p{Blank}(SEND|REPORT|[0-9]{3}?)(.*)\r\n",
Pattern.DOTALL | Pattern.CASE_INSENSITIVE);
Contrary to my expectation, running this code gave an average parse time of 21 sec. That’s 4 sec less than the buffer/char manipulation code. How did this happen?
A possible explanation could be that the char manipulations were not optimized as opposed to the reg-ex pattern which run at the system level. Another possible cause is the buffer copy operation in the original code. The reg-ex operate on the buffer without modifying or copying it. I had to leave the part at the end where the whole MSRP first line is deleted from the buffer (with a little bit more effort this could be getting rid of as well).
Case 5 – God Is In The Small Details
Now I really have to pick to the small things that bother me. One of them is the continuation pattern:
if(result) { // a boolean flag set to false at the beginning of a very long method
if(someCondition) {
// Do the success stuff
result = true;
} else {
// Do the failure stuff
result = false;
}
}
// ... Do something else
if(result) {
// And so on...
I don’t really like this way of doing things, but if you are already at it – why do you need line 4?
Also consider a well known performance killer – the logger (I’m sure every developer has come to know this silent assassin). If We remove all log lines from the code, the total parse time drops to 7 seconds. That is half a minute less than where we started. I don’t say do not use logs – just use them with discretion.
Conclusion
Not everything I tried during this case study was worth investing in. The major improvements were mainly in these area:
- Precompiling reg-ex once and not repeatedly
- Avoid char by char operations and prefer full buffer operations
- Whenever possible – give it to the system (e.g. reg-ex vs your own search and replace version, for example)
- Optimize whatever is called the most (even the innocent looking isCharSomething methods)
- Try to avoid at all cost buffer copying (and that include StringBuilder growing)
Think before you write your code, and use the appropriate optimization tools after that to optimize it (memory analyzers and method profilers mainly).
And as a final note – don’t take it personally. This article was meant for educational purpose. I have written some lousy code in my time, a lot worse than this parser. Feel free to contradict me. In fact, I don’t like to write code at all. What I really like is to delete code when possible (in Hebrew) 🙂